Bienvenue dans la deuxième partie de ma série de blogs en trois parties. Dans la première partie, j’ai passé en revue la terminologie courante de l’IA à un niveau supérieur. Dans ce blog, je vais explorer les différences entre l’apprentissage automatique et l’optimisation des décisions.
Si vous n’êtes pas titulaire d’un diplôme d’études supérieures dans un domaine scientifique, vous serez pardonné de ne pas connaître la différence entre l’apprentissage automatique et l’optimisation des décisions. En fait, vous avez peut-être entendu votre patron dire une version de ce qui suit : « nous devons optimiser ce processus avec l’apprentissage automatique ». Ce verbiage a-t-il un sens ?
Oui et non. D’un point de vue technique, les optimisations peuvent exister sans la présence de l’apprentissage automatique. En revanche, l’apprentissage automatique peut rarement exister sans une certaine forme d’optimisation. Je m’explique :
L’apprentissage automatique est un sous-ensemble de l’IA qui utilise la modélisation statistique pour permettre aux machines d’apprendre à partir de données. Vous soumettez des données à une structure mathématique prédéfinie et vous lui demandez d’apprendre les éléments nécessaires à la bonne exécution d’une tâche. Comment cet apprentissage s’effectue-t-il ? Dans la plupart des cas, les auteurs de l’algorithme ont créé ce que l’on appelle une fonction de coût pour évaluer les performances actuelles de la machine. Si la fonction de coût a une valeur élevée, la machine est peu performante, et si le coût est faible, la machine est performante. Nous utilisons alors certaines formes d’optimisation pour ajuster les paramètres du modèle afin de minimiser le coût. Ce réglage permet d’obtenir une machine plus performante que son état précédent, ce que l’on appelle généralement « apprentissage ».
Qu’entendez-vous par « structure mathématique prédéfinie » ?
Lorsqu’un chercheur publie un article décrivant une nouvelle méthode d’apprentissage automatique, il commence souvent par une structure non optimisée et décrit comment l’optimiser avec vos données pour qu’elle effectue correctement sa tâche. Imaginons que vous souhaitiez créer un modèle d’apprentissage automatique pour prédire le prix d’une maison en fonction de sa superficie. Vous pourriez commencer par une approche de type « line-of-best-fit », et dire que le prix peut être modélisé avec la structure suivante :
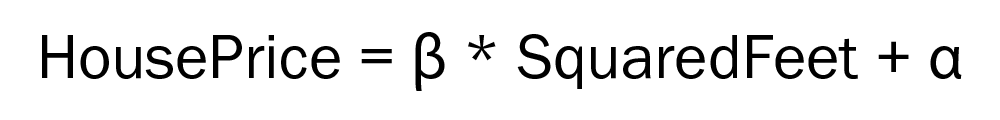
Si nous disposons de données, nous connaissons pour chaque maison le prix et la superficie en pieds carrés, mais qu’en est-il de ces mystérieuses quantités que sont A et B ? C’est ici que l’optimisation entre en jeu : l’auteur choisira une fonction de coût (dans ce cas, l’erreur au carré de votre prédiction) et minimisera ce coût en ajustant ces paramètres. Cela conduit à un modèle optimisé/entraîné.
Bon, nous savons que l’optimisation est utilisée dans l’apprentissage automatique, mais en quoi l’apprentissage automatique est-il différent de l’optimisation des décisions pure ?
Dans l’optimisation décisionnelle, c’est à vous de définir votre structure. Chaque fois que vous commencez une nouvelle optimisation, vous devez définir mathématiquement toutes les variables présentes dans votre système, les contraintes sur ces variables et la fonction objectif que vous essayez d’optimiser.
Par exemple : Dans les années 30, l’armée américaine a décidé d’appliquer l’optimisation des décisions pour minimiser le coût de l’alimentation de ses soldats. Ils ont construit la fonction qu’ils voulaient minimiser : la somme du coût de tous les aliments qu’ils donnent à un soldat. Évidemment, avec un tel problème, le coût minimum pour nourrir un soldat serait de 0$, puisque vous pourriez choisir de ne rien lui donner. Cela souligne la nécessité de définir nos contraintes : chaque soldat a une quantité minimale de chaque type de nutriment qu’il doit consommer chaque jour, ainsi qu’un apport calorique recommandé. Avec ces variables et ces contraintes définies, ils ont pu optimiser ce régime en minimisant les coûts pour le gouvernement américain, tout en maintenant des soldats en bonne santé.
Liste de choses à faire
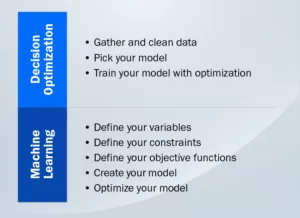
Vous avez peut-être remarqué que le problème de l’optimisation des décisions est plus complexe que celui du modèle d’apprentissage automatique. Cela s’explique par le fait que la personne qui applique l’optimisation a plus de latitude. Avec l’apprentissage automatique, il existe généralement un logiciel qui automatise la solution et la structure, mais dans l’optimisation, la structure dépend entièrement de vous. Les applications de l’optimisation des décisions sont donc plus susceptibles de tomber dans le piège du « garbage in, garbage out » : la solution optimale d’une structure mal définie n’a aucun sens.
La troisième partie : Comment appliquer l’IA de pointe à votre entreprise?

Oliver est un consultant senior en science des données chez KPI Digital, qui aide les clients à maximiser la valeur des données d’entreprise. Après avoir obtenu un baccalauréat en génie mécanique de l’Université McGill, il a poursuivi ses études à l’Institut de technologie de Géorgie dans le cadre de leur programme de maîtrise en sciences analytiques. Depuis lors, il se concentre sur la fourniture de solutions de science des données prêtes à être mises en production dans des domaines tels que la fabrication, l’ingénierie, la finance et la vente au détail.