Bienvenue au dernier volet de ma série de trois articles sur l’IA pratique. Dans le blog d’introduction, j’ai revu la terminologie de l’IA couramment utilisée à un niveau élevé. Dans le deuxième article, j’ai exploré les différences entre l’apprentissage automatique et l’optimisation des décisions.
Maintenant, il est enfin temps de discuter de la façon dont vous pouvez appliquer cela à votre entreprise.
Il est facile d’imaginer que les modèles les plus performants n’existent que derrière le mur payant d’un géant de la technologie, mais les techniques d’IA de pointe sont plus accessibles que vous ne le pensez. Cela ne veut pas dire que les sociétés FAANG ne mènent pas de recherches uniquement pour leur propre propriété intellectuelle privée, mais plutôt que la recherche publique sur les techniques d’IA est plus que suffisante pour répondre aux besoins de votre entreprise.
Où commence le cycle de vie d’un nouveau modèle d’IA ?
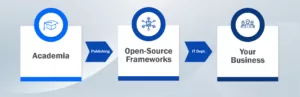
Tout commence dans le monde universitaire. Un chercheur choisit un problème courant et tente de concevoir un modèle performant capable de le résoudre de manière fiable. Un exemple populaire serait la détection d’objets : créer un modèle qui, à partir d’une image, peut prédire ce que l’ordinateur regarde. Un exemple très simple consiste à distinguer un chat d’un chien, mais ce problème a été étendu à la distinction rapide de milliers d’objets différents.
Lorsque l’institution de recherche est satisfaite, elle publie généralement ses travaux. Le contenu de cette publication peut varier, mais ils fournissent toujours un article, et parfois un code, des données et des paramètres de modèle à l’appui pour la reproductibilité.
Maintenant, le message est lancé. Si le modèle est novateur, les entreprises privées et les communautés open-source d’IA commencent à travailler pour reproduire elles-mêmes ces résultats. Si les entreprises privées réussissent, elles intègrent ce modèle dans leurs offres de services et font payer les utilisateurs pour l’exploiter. Si les projets open-source sont fructueux, ils diffusent le modèle pour une consommation publique gratuite. Il n’y a pas de course à la publication en soi, car chacun est libre de reproduire et de publier ces résultats à tout moment, mais le fait d’être le premier sur le marché présente des avantages.
Comment cela peut-il vous aider ?
Lorsque la communauté open-source reproduit les résultats de publications universitaires, elle met tout à la disposition de l’utilisateur gratuitement. Par exemple, si je souhaite utiliser un modèle de détection d’objets fiable et à jour, je peux le faire via des cadres gratuits tels que Tensorflow ou PyTorch, car ils ont fait le nécessaire pour mettre ces modèles à ma disposition de manière à ce qu’ils soient facilement utilisables. Je peux maintenant exploiter les modèles d’IA que les personnes les plus brillantes de la planète ont travaillé sans relâche pour m’offrir, sans payer un sou.
Si la version open-source est si bonne, pourquoi payer pour un service ?
Avec les offres open-source, les outils sont gratuits, mais le reste est à votre charge. Cela signifie que vous devez demander à votre service informatique de télécharger le modèle, de créer un service logiciel autour de celui-ci, de le déployer et de l’héberger sur l’un de vos serveurs ou dans le nuage. Si vous n’avez pas le luxe d’avoir un de ces gourous de l’informatique à votre disposition, peut-être simplement payer un service pour le construire et l’héberger pour vous. N’oubliez pas : L’IA est un outil, pas un produit.
Et si je trouvais un modèle presque parfait, mais qui ne répond pas tout à fait à mon problème ?
Bienvenue dans le monde merveilleux de l’apprentissage par transfert. L’apprentissage par transfert est une méthode axée sur le maintien des connaissances acquises lors de la résolution d’un problème et leur application à un problème différent mais connexe. Pourquoi est-ce important ? Si vous prenez un modèle générique capable d’effectuer une tâche, vous pouvez réentraîner certaines parties de celui-ci sur un nouvel ensemble de données semblable et lui faire effectuer une tâche légèrement différente. Par exemple, vous pouvez prendre un modèle de détection d’objets disponible publiquement, capable de classer des milliers d’objets différents, l’entraîner sur un ensemble relativement restreint de données d’images provenant de la chaîne de montage de votre entreprise et l’utiliser pour identifier des produits défectueux. Ce transfert de connaissances du modèle original vers ce nouveau domaine est faisable car la tâche de classification des produits défectueux sur votre chaîne de montage est suffisamment similaire aux tâches effectuées par un modèle de détection d’objets prêt à l’emploi. Tout à coup, avec un petit ensemble de données et un accès à la communauté open-source, vous pouvez appliquer la recherche de pointe à votre problème commercial très particulier.
L’omniprésence du développement open-source, combinée à la venue de l’apprentissage par transfert, ouvre d’innombrables voies pour utiliser l’IA de pointe dans votre entreprise. Heureusement, l’IA n’a jamais été aussi accessible qu’aujourd’hui, ce qui permet aux entreprises qui adoptent cette puissante technologie de bénéficier d’un avantage concurrentiel dans un paysage en évolution rapide.

Oliver est un consultant senior en science des données qui aide les clients à maximiser la valeur des données d’entreprise. Après avoir obtenu un baccalauréat en génie mécanique de l’Université McGill, il a poursuivi ses études à l’Institut de technologie de Géorgie dans le cadre de leur programme de maîtrise en sciences analytiques. Depuis lors, il se concentre sur la fourniture de solutions de science des données prêtes à être mises en production dans des domaines tels que la fabrication, l’ingénierie, la finance et la vente au détail.